Automation systems have always been designed to meet two key criteria: reliability and availability. Reliability is the first priority- data that enters the network should pass through it unchanged and should always make it to its destination. But availability is a more complex problem because it’s not just about moving bits across a network once they’re transmitted. Instead, availability means that no matter what happens to their physical boxes, those transmitters stay on. That’s where redundancy comes in to play. It’s is the mechanism to turn a reliable system into a highly available system, adding extra components to maintain reliable operation through a number of failures.
Redundant Applications
Over the years, parts of this redundancy concept have migrated from the user application running on a PLC down to the lower-level network protocol. For instance, a common failure in a distributed I/O system is a damaged Ethernet cable. Thus, PROFINET implemented the Media Redundancy Protocol (MRP) to handle media failures gracefully without requiring any intervention from the application running on top of PROFINET. But media redundancy is only part of system redundancy. Transmission media isn’t the only part of a network that can fail. Things like the transmitter, receiver, or anything in between can go down, too.
To address all of these failure modes, the most redundant systems are designed as fully-independent implementations that run in parallel. While that may work in smaller applications, scaling that kind of redundancy out to a factory floor or a building campus is usually cost-prohibitive. So, redundancy solutions are tailored to meet the specific availability demands based on their applications. For instance, parts of the system that are most prone to failure, like the network media or field I/O devices, are split out into smaller redundant systems.
Redundancy in PROFINET
PROFINET has four components of its redundant system: Media Redundancy, Controller Redundancy, Device Redundancy, and Network Redundancy.
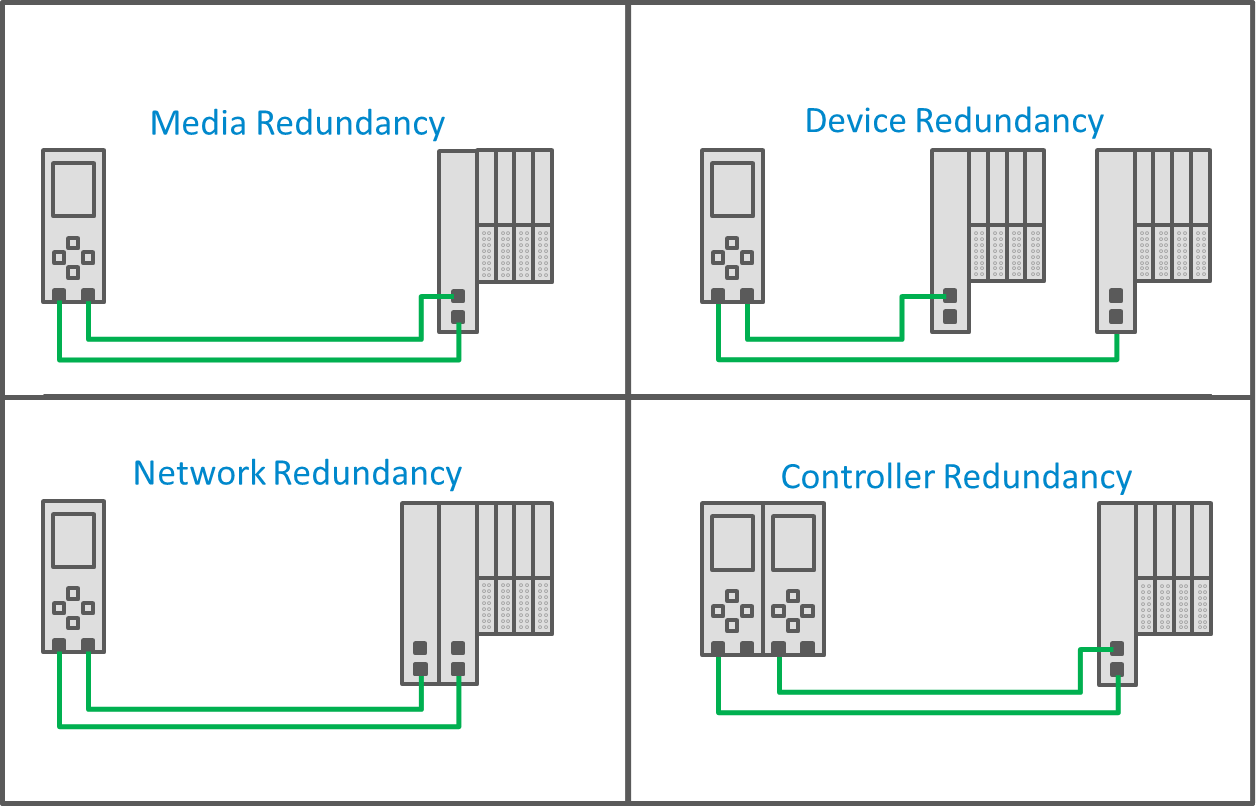
There are four types of redundancy built into the PROFINET protocol, each one addressing a unique failure mode within an automation system. Click to expand.
Of those four components, Media, Device and Network Redundancy are handled by the PROFINET network directly. While any PROFINET device with these features will be capable of redundant operation, controller redundancy is a complex issue. While PROFINET defines how redundant Controllers should interact with Devices, it doesn’t define how they should coordinate and work between themselves and their respective applications. Controller vendors and the applications running on those controllers must handle that coordination and control.
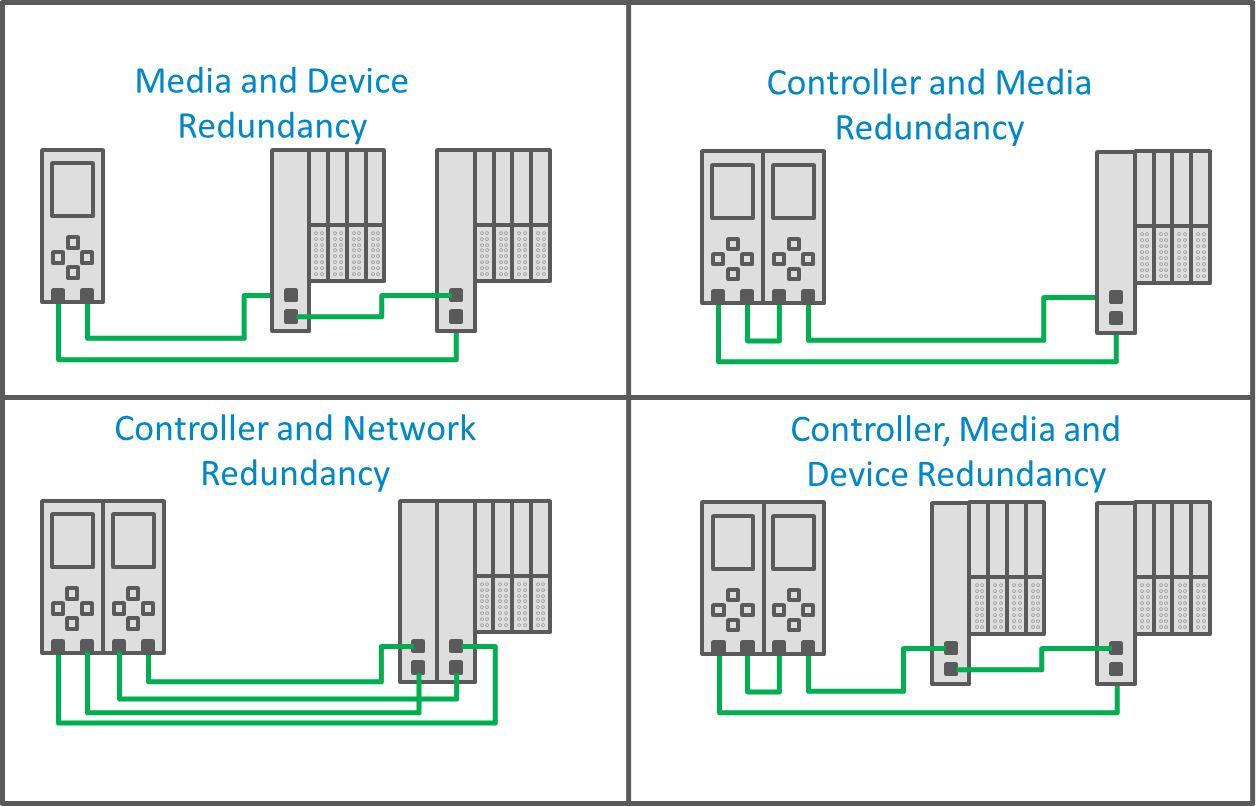
The four redundancy types can be combined to keep the system running through several types of failures. Only a few of the combinations are shown here. Click to expand.
This graphic is only a small sample of all of the redundancy configurations that are possible with PROFINET. There are too many combinations to list here, but the important thing is that in the most complex redundancy implementations, there can be multiple failures without affecting the system’s operation.
The layered approach to redundancy allows end users to choose how much complexity to build into their automation system. For more information on redundancy implementation your automation network, talk to your PROFINET vendor and see what they offer.
 Gain a deeper understanding of PROFINET by attending a PROFINET Certified Network Engineer Course.
Gain a deeper understanding of PROFINET by attending a PROFINET Certified Network Engineer Course.
These certification classes are intense, hands-on courses. You will learn how the underlying technology works from the application to the frame level. After passing both a practical and written exam, you become certified.
For more information, contact us or visit our website.