The concept of redundancy in PROFINET is broken into several parts: device, network, media, and controller redundancy. This article takes a look at controller redundancy and why it’s more complex than device redundancy.
There are two moving parts that make Controller redundancy work: coordination between controllers (usually some vendor-specific communication between PLC applications) and how devices handle simultaneous connections (a way to transmit data defined by the PROFINET protocol). Because the protocol only defines how devices should implement this feature, not all PROFINET systems can support controller redundancy.
Controller Redundancy in a normal state
Normally, two controllers connect to a device simultaneously. One controller establishes a primary connection that is identical to a regular PROFINET connection. The second controller establishes a special, “backup” connection. This connection doesn’t contain any valid output data and doesn’t allow the secondary controller to change any options on the device.
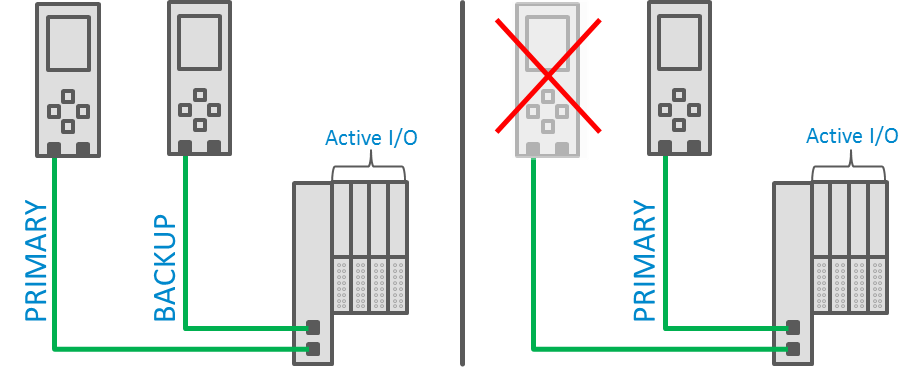
Normally, devices must maintain two simultaneous connections with redundant controllers. On the left, a device has one primary connection that contains valid output data, and the secondary connection contains invalid data. On the right, the device’s primary controller has failed. When the primary controller fails, the secondary controller requests control of the device and assumes the primary role.
Working through abnormal conditions
When the primary controller fails, a device doesn’t have the authority to use a backup connection as its new primary connection. The device has to play “follow the leader,” and wait for the backup controller to request a transition to primary status. This allows the new primary controller to coordinate the change across the entire PROFINET network, and prevents devices from transitioning individually.
After a device receives a transition request from the new primary controller, it has to do some book-keeping. It has to make sure that any alarms that were sent to the old primary controller made it successfully, make sure that the input data sent on the backup connection is current, and make sure there won’t be a big “bump” or change in the output data when it makes the transition. Once a device is sure that it can follow the transition request, it confirms the change with the new primary controller.
Meanwhile, the controller must coordinate this process with all of its connected PROFINET devices. While the underlying PROFINET “stack” handles all of the details of the transition, the application code that controls the stack has to be in the loop, too. The application code is responsible for monitoring the conditions that led to the transition, and making sure that the data it sends out to the devices is the same as the data that was sent by the old primary controller.
Coordination, complexity and cost
Controller Redundancy requires special coordination from both the PROFINET devices and controllers. And this coordination has a cost – it’s not easy to meet all of the requirements to build a device or a controller that supports redundancy. Because of this added cost and complexity, only some PROFINET devices and controllers support controller redundancy. Check with your PROFINET vendor to see whether this advanced redundancy technique works for your application.